上篇已经介绍了libco切入切出的相关代码与流程,本文主要学习协程切换时寄存器以及运行时栈的变化,也会涉及扩展部分的相关内容:共享栈,协程控制,协程池。另外本文并非完全原创,多处代码解释参考某大佬KM文章,有的代码细节还没有看懂,也有的地方加入了自己的看法与见解。
首先复习下进程的地址空间。
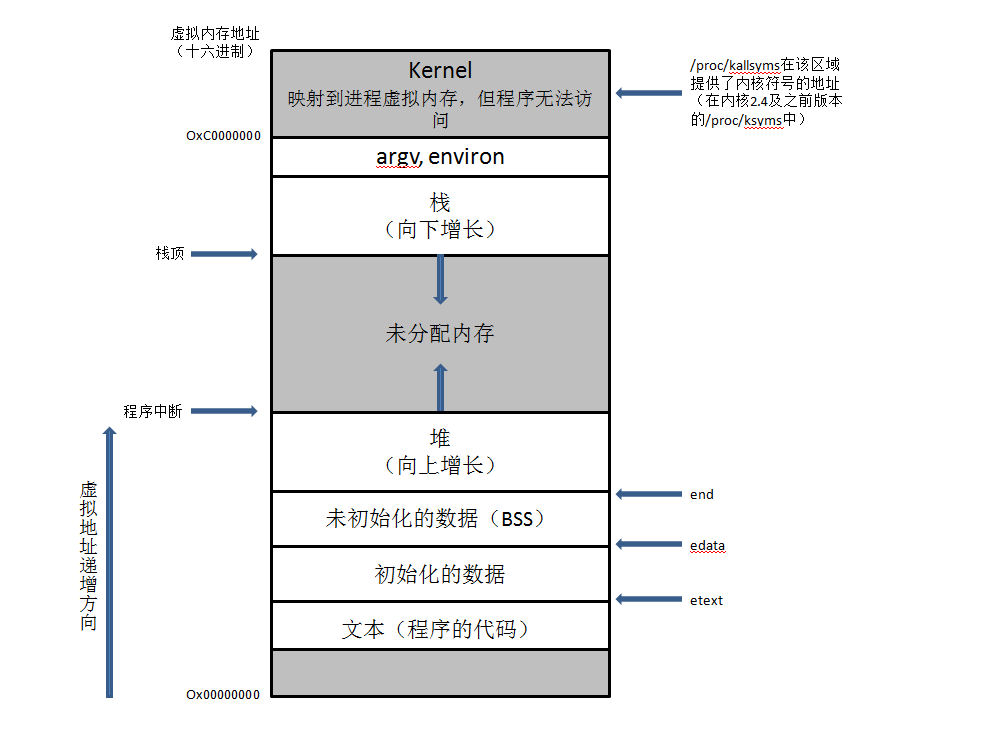
与协程相关的有代码段,堆,栈。代码段包含应用程序的汇编代码,指令寄存器eip存的是代码段中某一条汇编指令地址,cpu从eip中取出汇编指令的地址,并在代码段中找到对应汇编指令开始执行。cpu执行指令时在栈里存参数、局部变量等数据。代码通过malloc和new在堆中申请内存空间。
libco协程可以分为主协程和其他协程,主协程即当前线程,区别在于主协程的栈在进程空间的栈区,而其他协程的栈在堆区。正常的函数调用都发生在栈区,esp和ebp都在栈区波动,可以看出协程中的esp和ebp会跳到堆区。协程的切换上一篇已经介绍过了,resume切到某个协程,实质上就是将目标协程栈(堆)里保存的寄存器的值放到寄存器里,当前寄存器里的值保存到即将被挂起的协程栈里,然后改变运行时栈(修改esp,eip)来改变运行时序。
这里的协程切换详细说下,不过在此之前先介绍下函数调用时的堆栈状态更有助于理解libco里汇编描述的切换的过程。其实函数调用的汇编有一个框架:
call func -> enter -> … -> leave -> ret
这样好像看不出什么,但是如果把这些指令展开就可以看出1
2
3
4
5
6
7
8
9
10call = push eip
jmp func
enter = push ebp
mov esp ebp
leave = mov ebp esp
pop ebp
ret = pop eip
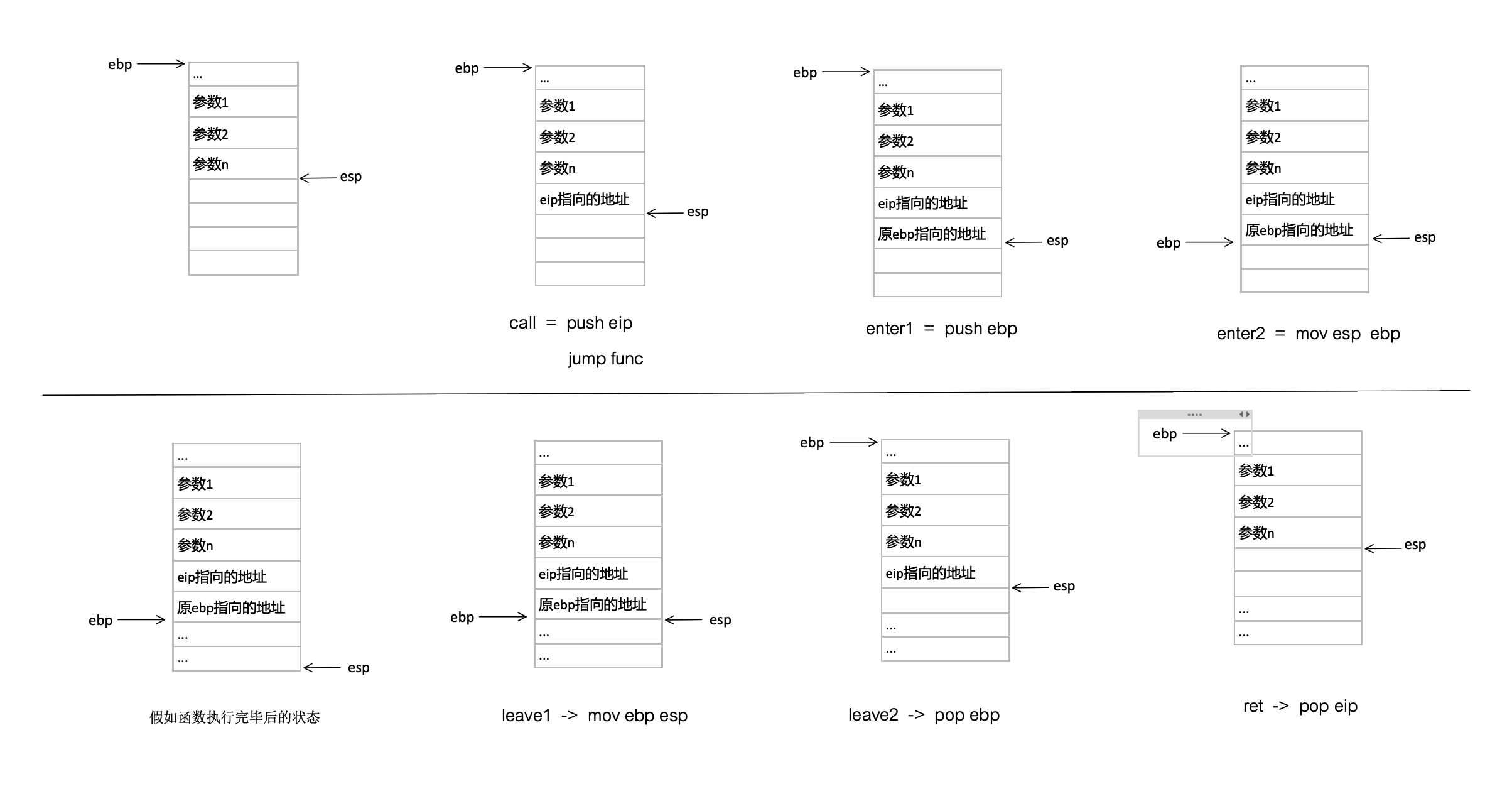
call与ret成对出现,enter与leave成对出现,一通操作后栈一切都恢复了调用前的原样。从这个角度出发,如果不让这些指令成对出现,自己去改变esp,ebp以及eip就可以实现从函数的任意位置切出去执行另一个函数的任意位置,然后再切回来。这里我们放大看一下libco的协程切换中esp,ebp,eip的改变:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48coctx_swap:
//此时要从当前运行的协程curr切换到目的协程pending_co
//此时esp存储的是返回地址,即coctx_swap后面的代码编译后的第一条汇编指令地址stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
//esp+4为curr->ctx的地址,也是curr->ctx.regs的地址,因为regs是ctx中第一个元素
//esp+8为pending_co->ctx的地址,也是pending_co->ctx.regs的地址,理由同上
#if defined(__i386__)
//leal取地址,将esp+4的地址存到eax,为什么要用leal而不是mov呢,因为这里要存储地址,使用mov就会存储该地址的值
leal 4(%esp), %eax //sp
//将esp指向了curr->ctx.regs的地址,注意此时已经不是在co_swap函数栈中了,已经切到了curr->ctx.regs位置
movl 4(%esp), %esp
//i386有void *regs[ 8 ],所以挪动4*8个地址,而且这里是leal,地址加操作,所以还可以得出一个有用的结论:
//对象内部成员先出现的在低地址,对象的地址最低,也是第一个成员的地址
leal 32(%esp), %esp //parm a : ®s[7] + sizeof(void*)
//原esp+4地址入栈,当curr再恢复时作为curr的esp
pushl %eax //esp ->parm a regs[7]: eax
pushl %ebp //regs[6]: ebp
pushl %esi //regs[5]: esi
pushl %edi //regs[4]: edi
pushl %edx //regs[3]: edx
pushl %ecx //regs[2]: ecx
pushl %ebx //regs[1]: ebx
//eax-4即原来的esp,也就是编译后的第一条汇编指令地址stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
//当下一次该协程被唤醒时只需要将regs[0]保存的pop到eip中就可以从这次切出去的位置继续执行了
pushl -4(%eax) //regs[0]: ret
//将esp指向了pending_co->ctx.regs的地址,注意此时已经不是在curr->ctx.regs中了,已经切到了pending_co->ctx.regs位置
movl 4(%eax), %esp //parm b -> ®s[0]
//从regs弹出返回地址,切到pending_co后pending_co需要执行的第一条指令地址
//第一次切到pending_co返回地址是CoRoutineFunc函数的地址,co_create中设置的(regs[EIP]=pfn...)
//第二次及以后切到pending_co返回地址是编译后的第一条汇编指令地址stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
popl %eax //ret func addr //regs[0]: ret
popl %ebx //regs[1]: ebx
popl %ecx //regs[2]: ecx
popl %edx //regs[3]: edx
popl %edi //regs[4]: edi
popl %esi //regs[5]: esi
popl %ebp //regs[6]: ebp
//弹出pending_co栈顶地址
//第一次切到pending_co弹出的esp指向ctx->ss_sp + ctx->ss_size - sizeof(coctx_param_t) - sizeof(void*)
//第二次及以后切到pending_co弹出的esp指向coctx_swap第一个参数所在栈的位置
popl %esp //regs[7]: eax
//这句和ret就是切换函数调用流程的灵魂,上面不是将上次挂起后/第一次运行的第一条指令地址存到eax中了么,
//这里将这个地址push到pending_co的协程栈中,下面ret=pop eip就将这条指令地址放到了eip中,coctx_swap执行完毕,执行eip中的指令,函数调用流程完美切换。
pushl %eax //set ret func addr
//eax清0
xorl %eax, %eax
ret
共享栈
每个协程在初始化时有一个stack_mem即运行时栈,如果是非共享栈则会分配128K的堆空间(后面所说的栈空间都是这个堆上),接下来协程运行过程中产生的临时变量、函数调用所有的都会在这个栈中分配。这样就会存在栈空间太大浪费或者空间不够用的情况。对于空间不够用可以多用new来新建临时变量,让其在堆中其他空间再分配,而不要分配到当前栈上。对于空间浪费问题就可以用共享栈来解决,共享栈仍然是在堆上,这对主协程没有影响,主协程的栈还在系统栈上。
采用共享栈时可以理解为协程切换以及运行中,esp和ebp都只在共享栈这块区域内变动,发生协程切换时需要把当前共享栈的状态保存到要被切出的协程的栈中。这样有个好处就是每个协程所持有的栈空间大小是按需分配的,自然会节省大量内存。同样带来的缺点就是协程切换时的栈拷贝,共享栈其实就是用时间换空间。
为了避免协程切换时频繁发生栈拷贝,可以申请多个共享栈。比如申请两个共享栈,协程运行顺序为协程1->协程2->协程1。如果用取模的方式来分配共享栈,那么协程1用栈1,切到协程2时协程2用栈2,栈1不用拷贝,再切回栈1时栈2也不用拷贝。当然寄存器每次发生协程切换都要有拷贝保存的操作(coctx_swap)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co)
{
stCoRoutineEnv_t* env = co_get_curr_thread_env();
//get curr stack sp
//记录curr协程栈的位置,后面再切回curr协程时,将保存的curr协程栈内容拷贝到stack_sp所指的空间
char c;
curr->stack_sp= &c;
if (!pending_co->cIsShareStack)
{
env->pending_co = NULL;
env->occupy_co = NULL;
}
else
{
env->pending_co = pending_co;
//get last occupy co on the same stack mem
//获取要切到的协程将要使用的共享栈现在正在被哪个协程使用
stCoRoutine_t* occupy_co = pending_co->stack_mem->occupy_co;
//set pending co to occupy thest stack mem;
//将那个共享栈记录修改为pending_co正在使用
pending_co->stack_mem->occupy_co = pending_co;
//在全局变量env中记录下那个共享栈被“霸占”的协程
//不能记录在局部变量中,因为协程切换后curr协程中的内容不可以被pending_co读
env->occupy_co = occupy_co;
if (occupy_co && occupy_co != pending_co)
{
//occupy_co协程栈内容保存到save_buffer,从occupy->stack_sp(低地址)保存到occupy->stack_mem->stack_bp(高地址)
save_stack_buffer(occupy_co);
}
}
//swap context
//保存curr寄存器内容,恢复pending寄存器内容,切换ebp,esp使其指向pending_co的协程栈
coctx_swap(&(curr->ctx),&(pending_co->ctx) );
//stack buffer may be overwrite, so get again;
//此时运行的协程是pending_co,切到pending_co执行的第一条代码就是下面这条指令。
stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
stCoRoutine_t* update_occupy_co = curr_env->occupy_co;
stCoRoutine_t* update_pending_co = curr_env->pending_co;
if (update_occupy_co && update_pending_co && update_occupy_co != update_pending_co)
{
//resume stack buffer
//如果pending_co第一次运行,save_buffer为空,不会执行下面的memcpy
if (update_pending_co->save_buffer && update_pending_co->save_size > 0)
{
//pending_co之前切出时记录了栈低地址位置stack_sp=&c
//所以pending_co再切回时将保存的pending_co栈内容复制到stack_sp指向的空间
memcpy(update_pending_co->stack_sp, update_pending_co->save_buffer, update_pending_co->save_size);
}
}
...
}
协程控制
libco使用的是epoll多路复用IO模型,非阻塞IO,发起read/write操作后即可挂起协程,调度其他协程执行,等数据就绪后唤醒该协程继续执行。所以协程在写法上非常友好,不需要像异步IO那样定义回调函数,read/write完即可继续写后续的逻辑。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35ssize_t read( int fd, void *buf, size_t nbyte )
{
HOOK_SYS_FUNC( read );
if( !co_is_enable_sys_hook() )
{
return g_sys_read_func( fd,buf,nbyte );
}
rpchook_t *lp = get_by_fd( fd );
if( !lp || ( O_NONBLOCK & lp->user_flag ) )
{
ssize_t ret = g_sys_read_func( fd,buf,nbyte );
return ret;
}
int timeout = ( lp->read_timeout.tv_sec * 1000 )
+ ( lp->read_timeout.tv_usec / 1000 );
struct pollfd pf = { 0 };
pf.fd = fd;
pf.events = ( POLLIN | POLLERR | POLLHUP );
int pollret = poll( &pf,1,timeout );
ssize_t readret = g_sys_read_func( fd,(char*)buf ,nbyte );
if( readret < 0 )
{
co_log_err("CO_ERR: read fd %d ret %ld errno %d poll ret %d timeout %d",
fd,readret,errno,pollret,timeout);
}
return readret;
}
这里是自定义的read函数hook住系统read函数,前面都是对其他情况的兼容,比如用户没有开启hook则直接调用系统read;如果指定了非阻塞也直接调用系统read,此时为非阻塞。重点在于调用poll挂起当前协程,直到有数据就绪或者超时时,协程才会被重新调度。
write也是类似的逻辑,不同之处在于read不知道要读多少字节,所以只读一次;而write知道要写多少字节,所以每次写如果没有全部写完,则需要重新加入到poll中直到写完/写出错才会停止1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26ssize_t write( int fd, const void *buf, size_t nbyte )
{
...
size_t wrotelen = 0;
while( wrotelen < nbyte )
{
struct pollfd pf = { 0 };
pf.fd = fd;
pf.events = ( POLLOUT | POLLERR | POLLHUP );
poll( &pf,1,timeout );
writeret = g_sys_write_func( fd,(const char*)buf + wrotelen,nbyte - wrotelen );
if( writeret <= 0 )
{
break;
}
wrotelen += writeret ;
}
if (writeret <= 0 && wrotelen == 0)
{
return writeret;
}
return wrotelen;
}
协程hook住了底层socket族函数(read,write,recv,send…),设置了O_NONBLOCK,调用socket族函数后,调用poll,此处的poll是自定义的poll,里面又调用了co_poll_inner,在该函数中创建了epoll描述符,设置就绪fd的回调函数OnPollProcessEvent来切回到对应协程,并记录切回协程之前需要做的一些预操作处理函数OnPollPreparePfn,然后加入epoll的红黑树和超时队列,挂起协程让其他协程执行,所有协程都挂起后通过eventloop在主协程里检查注册的IO事件,若就绪或超时则切到对应协程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72void co_eventloop( stCoEpoll_t *ctx,pfn_co_eventloop_t pfn,void *arg )
{
...
for(;;)
{
int ret = co_epoll_wait( ctx->iEpollFd,result,stCoEpoll_t::_EPOLL_SIZE, 1 );
stTimeoutItemLink_t *active = (ctx->pstActiveList);
stTimeoutItemLink_t *timeout = (ctx->pstTimeoutList);
memset( timeout,0,sizeof(stTimeoutItemLink_t) );
for(int i=0;i<ret;i++)
{
stTimeoutItem_t *item = (stTimeoutItem_t*)result->events[i].data.ptr;
if( item->pfnPrepare )
{
item->pfnPrepare( item,result->events[i],active );
}
else
{
AddTail( active,item );
}
}
unsigned long long now = GetTickMS();
TakeAllTimeout( ctx->pTimeout,now,timeout );
stTimeoutItem_t *lp = timeout->head;
while( lp )
{
//printf("raise timeout %p\n",lp);
lp->bTimeout = true;
lp = lp->pNext;
}
Join<stTimeoutItem_t,stTimeoutItemLink_t>( active,timeout );
lp = active->head;
while( lp )
{
PopHead<stTimeoutItem_t,stTimeoutItemLink_t>( active );
if (lp->bTimeout && now < lp->ullExpireTime)
{
int ret = AddTimeout(ctx->pTimeout, lp, now);
if (!ret)
{
lp->bTimeout = false;
lp = active->head;
continue;
}
}
if( lp->pfnProcess )
{
lp->pfnProcess( lp );
}
lp = active->head;
}
if( pfn )
{
if( -1 == pfn( arg ) )
{
break;
}
}
}
...
}
上述为主协程调用eventloop片段。首先用co_epoll_wait找出所有就绪的fd,将就绪fd从超时队列pTimeOut移除并加入到就绪队列pstActiveList。TakeAllTImeout拿出超时队列里的所有超时元素并加入到就绪队列pstActiveList。在遍历就绪队列时有一个是否超时的判断,没有超时的再重新加入到超时队列,因为TakeAllTImeout取出的不一定是真正的超时事件,超时队列底层实现是60000大小的循环数组,存放每毫秒(共60000毫秒)的超时事件,每个数组的元素均是一条链表,循环数组的目的是便于通过下标找到所有超时链表。例如超时时间是10毫秒的所有事件均记录在数组下标为9(在循环数组实际的下标可能不是9,仅举个例子)的链表里,所有超时时间大于60000毫秒的事件均记录在数组下标为59999的链表里。如果取出超时时间是60000毫秒的事件,TakeAllTimeout会把超时时间大于60000毫秒的也取出来,因此需要再把超时时间大于60000毫秒的重新加回超时队列。
事件超时或者就绪时调用pfnProcess即OnPollProcessEvent切回协程(该参数在调用poll中设置),此时协程是第k次(k>1)次切回,从上次切出的地方继续执行(poll–>co_yield_env–>co_swap–>stCoRoutineEnv_t* curr_env = co_get_curr_thread_env())1
2
3
4
5void OnPollProcessEvent( stTimeoutItem_t * ap )
{
stCoRoutine_t *co = (stCoRoutine_t*)ap->pArg;
co_resume( co );
}
除了epoll激活协程外还可以使用超时来激活协程,可以调用poll(NULL, 0, duration)设置协程挂起duration秒后激活重新运行。poll是被hook住的函数,执行poll之后,当前协程会被加到超时队列pTimeOut,并被切换到其他协程,所有协程挂起后,主协程扫描超时队列,找到超时的协程,并切换。因此可用poll实现协程的睡眠。注意不可用sleep,因为sleep会睡眠线程,线程睡眠了,协程无法被调度,所有的协程也都不会执行了。
协程池
协程池的好处是不用每次使用协程时都创建新的协程。创建新协程主要开销有两个:一,需要malloc协程环境stCoRoutine_t,stCoRoutine_t有4K大小的协程私有变量数组;二,协程栈128K。每次创建新的协程要分配这么大的空间需要有时间开销,另外频繁申请、销毁会导致内存碎片的产生。即使在共享栈模式下不用为每个协程申请协程栈,也会有第一部分stCoRoutine_t的开销。每次从协程池取出协程后,将stCoRoutine_t.pfn重新初始化为用户自定义的协程函数即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37static void* worker_main(void* arg) {
CWorker* worker = (CWorker*)arg;
while (true) {
if (worker->func_) {
worker->func_();
}
worker->func_ = NULL;
if (g_worker_pool.gc_stack_size_ > 0) {
FreeStackRss(worker->co_->stack_mem->stack_buffer);
}
g_worker_pool.workers_.push(worker);
co_yield_ct();
}
return NULL;
}
void ProcessByWorker(std::function<void(void)> func1) {
CWorker* worker = NULL;
if (g_worker_pool.workers_.empty()) {
stCoRoutineAttr_t attr;
attr.stack_size = g_worker_pool.hard_limit_stack_size_;
stCoRoutine_t* worker_routine = NULL;
worker = new CWorker(worker_routine);
co_create(&worker_routine, &attr, worker_main, worker);
worker->co_ = worker_routine;
} else {
worker = g_worker_pool.workers_.top();
g_worker_pool.workers_.pop();
}
if (worker == NULL) {
return;
}
worker->func_ = func1;
co_resume(worker->co_);
}
TODO list
1 libco的demo都学习下,出一篇博客
2 协程池学习procebyworker
内网
github