来鹅厂快半年,上过一次Linux性能分析与调试工具的课程,当时只是拍了照片,听的比较懵逼,一次性没法消化,现在整理下,一来备忘,二来需要时可以快速查到。
perf
perf可以对指定的进程或者事件进行采样,用来找出应用程序或者内核的热点函数,找到哪个函数cpu占比比较高,从而定位性能瓶颈。
比较常用的有perf top,perf record, perf report, perf stat,还有perf list,perf list用来列出支持哪些性能事件。此文对其不做过多介绍。
perf top
perf top可以显示某个应用进程或者当前机器上(root权限)中占用cpu时钟最多的函数或者指令。
写了一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13示例1
using namespace std;
void add(int &i){
++i;
}
int main(){
int i = 0;
while(1){
add(i);
}
return 0;
}
可以在root下直接运行perf top: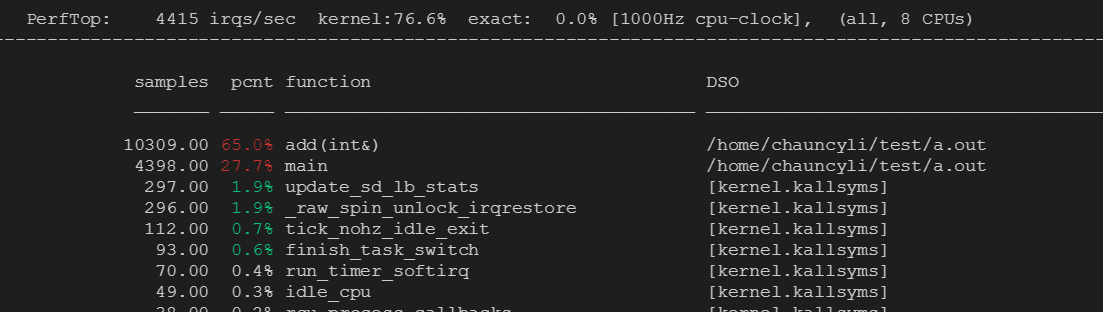
输出结果包含四列:
- samples:采样数。采样总数中,有多少次是该事件
- pcnt:该事件在所有采样中所占的比例
- function:事件符号名/函数名,有时没法用函数名表示会显示一串地址
- DSO:Dynamic Shared Object,可以是应用程序、内核、动态链接库、模块。
也可以在当前用户下找到运行的进程,指定进程号从而对某个进程进行采样分析。
常用命令参数:
-p
-k
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d
-g:得到函数的调用关系图。
最近在做进程性能压测,实测一般情况perf top确实好用,刚压测时显示vprintf函数耗时高,才突然想起忘记调整日志级别。不过到了性能瓶颈时,它就不能马上看出哪里需要优化了。比如这次压测故事线,perf top显示最耗时的是free/malloc,而且所占cpu比并不高(5%),但也标红了。这时应该要需要从设计层进行优化了吧(个人认为)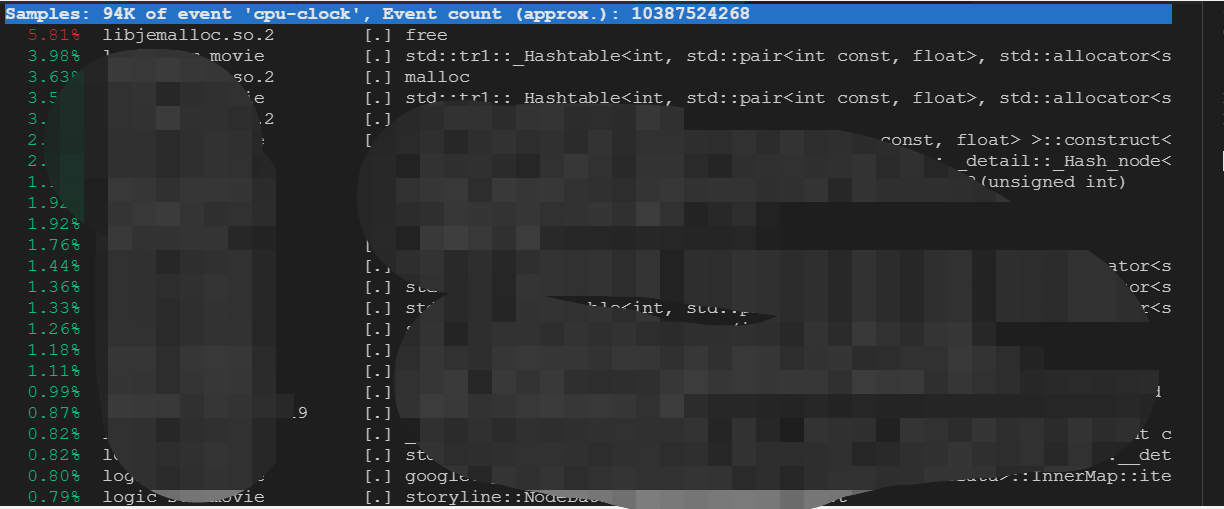
perf record,perf report
perf top可以实时显示性能信息,但是不可以保存数据,没有办法离线或者进行后续的分析。perf record提供了保存数据的功能,它可以将性能数据保存到当前目录下的perf.data里,使用perf report进行展示。
perf record运行时当前窗口会阻塞,需要ctrl-c结束采样与记录,采样记录没有结束时perf.data不可以查看与展示。
可以直接perf record ./a.out,即直接跟可执行程序,可以通过-p指定进程号。不过一般可执行程序并不是./就可以运行,建议使用-p进程号。
上述示例的perf report结果: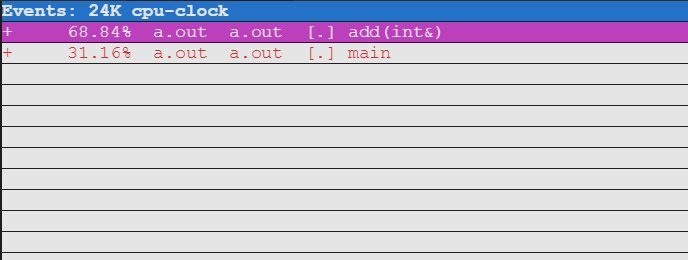
perf stat
perf stat可以分析应用程序某次执行的性能状况,一般7*24h运行的后台程序不太适合用这种方法。1
2
3
4
5
6
7
8
9
10
11
12
13//示例2
using namespace std;
void add(int &i){
++i;
}
int main(){
int i = 0;
for(int j = 0 ; j < 10000; j++){
add(i);
}
return 0;
}
perf stat适用于分析这种可以执行完的“有头有尾”的程序。效果如下: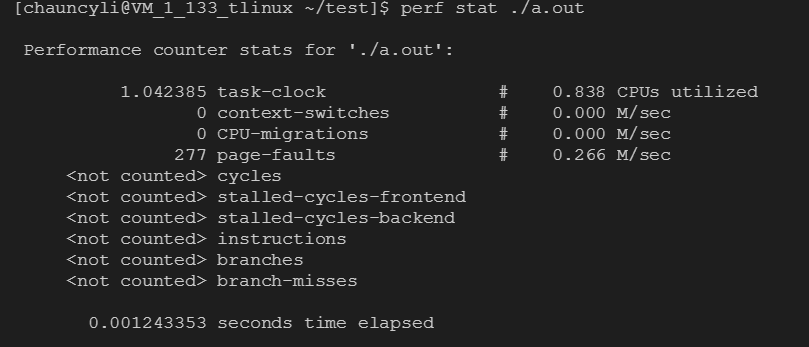
也可以使用-r参数指定执行多次,从而获得平均数据: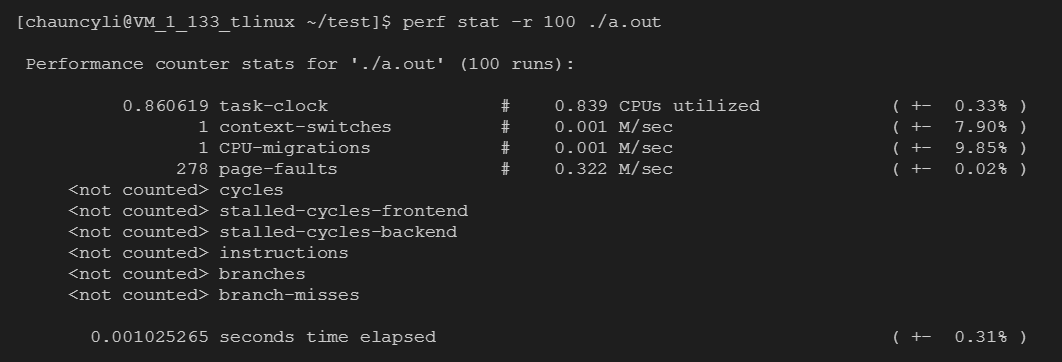
也可以分析Linux命令: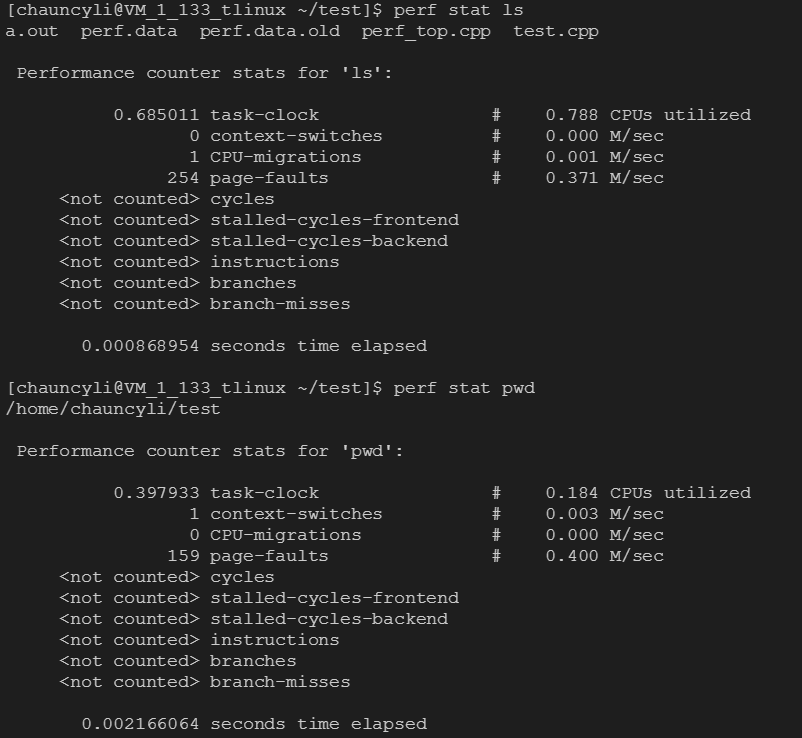
看出分析包含10个性能数据统计:
task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:上下文的切换次数。
CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。可以用cycles / task-clock算出。
stalled-cycles-frontend:略过。
stalled-cycles-backend:略过。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。
常用参数:
-p:stat events on existing process id (comma separated list). 仅分析目标进程及其创建的线程。
-a:system-wide collection from all CPUs. 从所有CPU上收集性能数据。
-r:repeat command and print average + stddev (max: 100). 重复执行命令求平均。
-C:Count only on the list of CPUs provided (comma separated list), 从指定CPU上收集性能数据。
-v:be more verbose (show counter open errors, etc), 显示更多性能数据。
-n:null run - don’t start any counters,只显示任务的执行时间 。
-x SEP:指定输出列的分隔符。
-o file:指定输出文件,–append指定追加模式。
–pre \
–post \
ltrace,strace
ltrace用来跟踪一个进程的库函数调用情况;strace用来跟踪一个进程的系统调用或信号产生的情况。这两个命令既可以调试一个新的程序,也可以调试某个正在运行的进程,使用方式类似。
常用参数:
-f :除了跟踪当前进程外,还跟踪其子进程。
-o file :将输出信息写到文件file中,而不是显示到标准错误输出(stderr)。
-p pid :绑定到一个由pid对应的正在运行的进程。此参数常用来调试后台进程。
-D :在每行输出中打印相对时间戳,即该调用所消耗的时间
后面学习到高阶工具继续更…