B树
概述
B树与B+树其实还是一种查找技术,但是平衡二叉树的时间可达O(logn)了呀,无论比较次数还是查找次数都是最小的,为啥还要有B树的存在(这是我在第一次看到B树时的疑惑….too young too naive!)。
好多的数据结构与数据处理其实都是在内存中进行的,考虑的都是内存中的运算时间复杂度。但如果需要操作的数据集非常大,比如数据库中的数据表,硬盘中上万个文件等数据量比较大的时候,索引的大小可能有几个G甚至更多,显然不可能把整个索引都加载到内存,能做的只有逐一加载每一个磁盘页,这里的磁盘页对应着索引树的结点。此时就需要不断的从外存将数据调入内存进行处理了。
我们都知道访问外存要比访问内存慢的多。也就是说访问一次内存的时间相对于访问一次外存的时间可以忽略不计。所以现在的目的就是要尽可能的减小访问外存的次数。
二叉树,AVL树,RB-tree,等等数据结构每个结点只能用有两个孩子,并且自身只能存储一个元素。在元素非常多的时候,树的高度非常大。这就使得访问外存次数非常多。
所以,多路查找树诞生了!
多路查找树的每个结点的孩子可以多于两个,并且每个结点可以存储多个元素。其特征之一就是让树尽可能的矮胖,从而减少磁盘IO次数。
B树是一种多路平衡查找树,它的每一个结点最多包含k个孩子,k被称为B树的阶。k的大小取决于磁盘页的大小。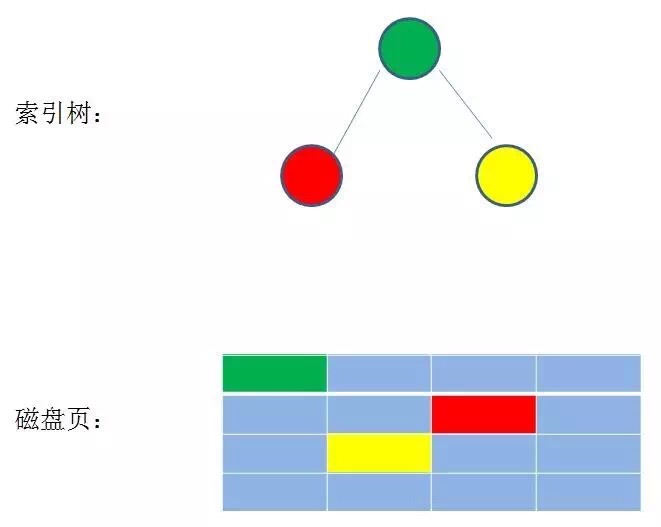
一个m阶B树具有如下特征:
- 如果根结点不是叶子结点,则其至少有两棵子树
- 树中每个非终端结点都包含k-1个元素和k个孩子(m/2<=k<=m)
- 每个叶子结点都包含k-1个元素(m/2<=k<=m)
- 所有叶子结点都位于同一层,,并且不携带信息(可以看做是查找失败的标记)
- 所有分支结点包含下列信息数据(n,A0,K1,A1,K2…Kn,An),其中:Ki(i=1,2,3…n)为关键字且Ki<K(i+1);Ai(i=0,2…n)为指向子树根结点的指针,且指针A(i-1)所指子树中所有结点的关键字均小于Ki,An所指子树中的关键字均大于Kn,n(ceil(m/2)-1<=n<=m-1)为关键字的个数
例如: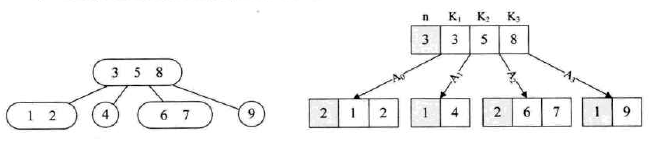
查找7时,首先从外存中选中3 5 8所在的结点调入内容,查找后发现7并不在其中,但是在5和8之间,因此通过A2再读取6 7 结点,查找到所需元素。
可见B树的查找过程是一个顺指针查找结点和在结点的关键字中进行查找交叉进行的过程
分析
查找
在B树上进行查找包含两种操作:
- 在B树中找结点
- 在结点中找关键字
由于B树通常存储在磁盘上,则前一操作是在磁盘上进行的,在磁盘上找到指针所指结点,然后调入内存;后一操作是在内存中进行,利用二分查找查询。显然在磁盘上进行一次查找比在内存中的查找耗时要多的多。因此磁盘IO次数,即B树的深度是决定B树查找效率的首要因素。
现考虑最坏情况,即待查结点在B树上的最大层次数。也就是含N个关键字的m阶B树的最大深度是多少
类似AVL树的讨论,先看深度为l+1的m阶B树所具有的最少结点数。
根据B树定义,第一层至少有1个结点,第二层至少有2个结点,由于除根结点外,每个非终端结点至少有ceil(m/2)棵子树,故第三层有2*ceil(m/2)个结点,第四层有2*ceil(m/2)\^2个结点。第l+1层至少有2*ceil(m/2)^(l-1)个结点。
若m阶B树中有N个关键字,则叶子结点为N+1。即:1
2
3N+1>=2*ceil(m/2)^(l-1)
l-1<=log~ceil(m/2)~(N+1)/2 //ceil(m/2)是底数,(N+1)/2是指数
l<=log~ceil(m/2)~(N+1)/2+1
也就是说,在含有N个关键字的B树上进行查找时,从根结点到目标结点路径上涉及的关键字不超过log~ceil(m/2)~(N+1)/2+1。
插入
由于B树定义每个结点的子树至少为ceil(m/2)个,故每个结点所含有的关键字至少为ceil(m/2)-1个至多m-1个。与二叉树的插入不同,二叉树的插入是每次插入一个叶子结点,而B树是在最底层的某个非终端结点中添加一个关键字,如果该结点的关键字数量不超过m-1,则直接插入完成;如果大于m-1,则需要对该结点进行分裂,将中间的关键字合并到双亲结点中,如果双亲结点关键字数量也超过m-1,继续向上合并,如果根结点也超过m-1,则产生一个新的根结点,即原B树长高。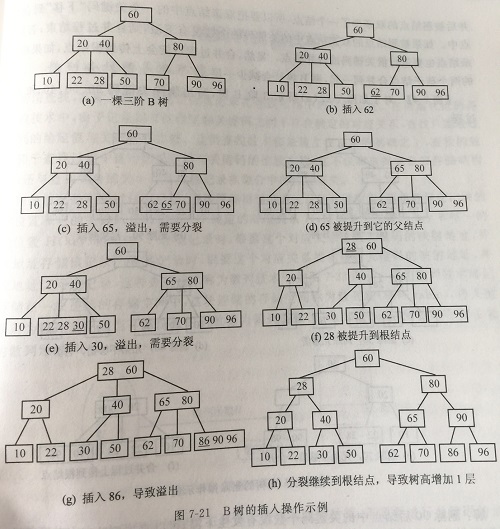
删除
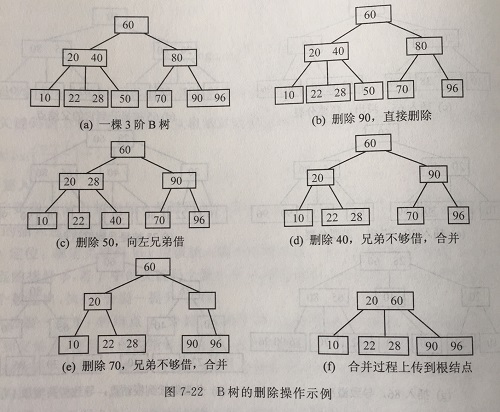
设在m阶B树中删除关键字key,先定为key所在结点的指针q,假定key是结点q中的第i个关键字Ki,若结点q不是终端结点,则用Ai所指的子树中的最小值x来替换Ki,由于x所在结点一定是终端结点,这样,删除问题就归结为在终端结点中删除关键字。
如果终端接结点的关键字数量大于ceil(m/2)-1,则直接删除,否则不符合B树定义,需要分两种情况处理:
- 兄弟够借。查看相邻兄弟结点,如果兄弟结点有足够多的关键码(大于ceil(m/2)-1),就从兄弟结点中借来一个关键字,为保持B树特性,将借来的关键字上移到被删结点的双亲结点中,同时将双亲结点中的相应关键字下移到被删结点中。
- 兄弟不够借。如果没有一个兄弟结点可以把关键字借给被删结点,那么被删结点就需要把它的一个关键字让给其一个兄弟结点,即执行合并操作,并且把这个空节点删除。合并后被删结点的双亲少了一个结点,所以要把双亲结点的一个关键字下移到合并结点中去,如果被删结点的双亲结点中的关键字的个数没有下溢,则合并过程结点,否则,双亲结点也要进行借关键字或合并结点。如果合并过程上传到根结点,如果根结点的两个孩子结点合并到一起,则B树就会减少一层。
B+树
B+树是应文件系统所需而出的一种B树的变形树,它有着比B树更加高效的查询操作(跪了!)。
一棵m阶的B+树与B树的差异在于:
- 有n棵子树的结点中含有n个关键字(B树是n-1个)
- 所有的叶子结点中包含了全部关键字的信息,以及指向这些关键字的指针,且叶子结点本身依关键字的大小自小而大顺序链接。(B树中的叶子结点是查询失败的标志)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树中的最大(最小)关键字(B 树的非终节点也包含需要查找的有效信息)
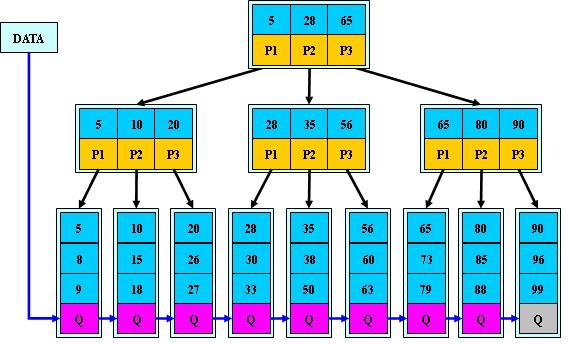
分析
1) B+tree的磁盘读写代价更低
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树的查找类似于B树,B+树的插入仅在叶子结点上进行,当结点中的关键字个数大于m时要分裂成两个结点,它们所含关键字的个数都为ceil((m+1)/2),并且它们的双亲结点中的应同时包含这两个结点的最大关键字。
B+树的删除也仅在叶子结点中进行,当叶子结点中的最大关键字被删除时,其在非终端结点中的值可以作为一个分界关键字存在。如果因为删除而使得结点中的关键字个数少于ceil(m/2)时,其和兄弟结点的合并过程类似于B树。
如果没有看明白可以参考下这篇博客
参考资料:
《数据结构——严蔚敏》
《数据结构——从概念到C实现》
《大话数据结构——程杰》