目录:
简单选择排序
概述
通过n-i次关键字间的比较,从n-i+1个记录中选取关键字最小的记录,与第i个记录交换。
实现
1 | void swap(int &a,int &b){ |
复杂度
不管初始序列情况,比较次数总是n*(n-1)/2,(根据梯形公式或者等差数列求和可得),交换次数最佳为0次,最差为n-1次,故最后的时间复杂度为O(n^2), 相比较与冒泡排序的O(n^2),简单选择排序的性能略优,因为其记录移动的次数少,我们知道,在计算机底层修改记录的步骤是:从磁盘将数据取到寄存器->修改寄存器的值->将修改后的值存回磁盘。
堆排序
概述
在简单选择排序中,其比较次数不会改变,可以考虑利用前一趟的比较信息,可以减少后续的比较次数,这种算法称为树形选择排序,又称锦标赛排序。是一种按照锦标赛的思想进行选择排序的方法。首先对n个元素进行两两比较,然后在其中ceil(n/2)个较小者之间再进行两两比较(ceil(x)即不小于x的最小整数),如此重复,直到选出最小关键字为止。这个过程可以利用一棵有n个叶子节点的完全二叉树表示。
由于含有n个叶子结点的完全二叉树的深度为ceil(logn)+1,则在树形选择排序中,除了最小关键字之外,每选择一个次小关键字,要进行ceil(logn)次比较,因此其时间复杂度为O(nlogn)。但是,其缺点也很明显:辅助存储空间较大,最大值多余比较。
为了弥补树形选择排序的缺点,堆排序诞生了!
堆排序只需要一个记录大小的辅助空间,每个待排序列的记录仅占有一个存储空间。
堆的定义如下:n个元素的序列{k1,k2,…kn},当且仅当满足以下条件时称之为堆。
{ki<=k(2i) , ki<=k(2i+1)} 或 {ki>=k(2i) , ki>=k(2i+1) },1<=i<=floor(n/2)
用完全二叉树表示时即表明,非终端结点的值均不大于(或不小于)左右孩子结点的值。由此,堆顶元素必须为最小(或最大)元素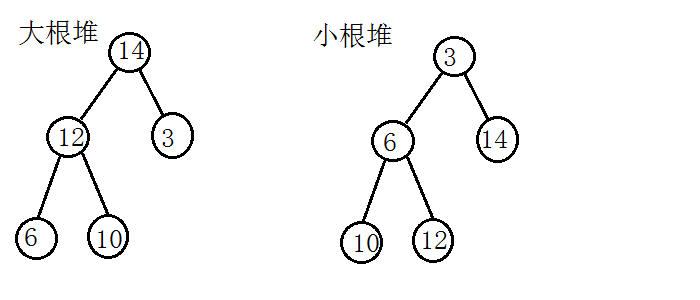
算法描述
堆排序就是利用堆(假设利用大根堆)进行排序的方法,它的基本思想是,将待排序列构造成一个大根堆。此时,整个序列的最大值就是堆顶元素,然后将它与堆的最后一个元素互换,此时最后一个元素即为最大值。将剩余的n-1个元素重构大根堆,找到次大的元素,再交换,依次类推,最后即可得到一个递增的序列。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25void swap(int &a,int &b){
int temp = a;
a = b;
b = temp;
}
void HeapAdjust(int a[],int s,int m){
int temp = a[s];
for(int j = s*2;j<=m;j*=2){
if(j<m && a[j]<a[j+1])
j++; //找到字节的中的较大值
if(temp>=a[j]) //当前根结点最大则不用交换
break;
a[s] = a[j];
s = j;
}
a[s] = temp;
}
void HeapSort(int a[],int n){ //数组从下标1开始存储,存储n个元素
for(int i = n/2;i>0;i--)
HeapAdjust(a,i,n); //大根堆的构建
for(int i = n;i>1;i--){
swap(a[i],a[1]);
HeapAdjust(a,1,i-1); //将a[1...i-1]重新调整为大根堆
}
}
完整测试代码见本人GitHub
关于代码的几点说明:
HeapSort中的第一个for为什么从n/2开始循环而不是n?
从n/2到1都是有孩子的结点。我们所谓的将待排序列构成一个大根堆,其实就是从下向上,从右向左,将每个非终端结点(非叶子结点)当做根结点,将其与子树调整为大根堆。
HeapAdjust中的循环,为什么j从2*s开始,又为什么以j*=2递增呢?
根据完全二叉树的性质,下标为s的结点其左孩子为2*s,右孩子为2*s+1,同理,它的孩子的孩子下标就是以2的位数序号增加
为什么每次要将根结点与最后一个元素互换?
堆排序的思想是每次将最大的元素放到一维数组的最后一个位置,次大倒2,一次类推,故有此举
复杂度分析
它的运行时间主要消耗在初始构建堆和在重构堆时的反复筛选上。在构建堆的过程中,因为是从完全二叉树的最下层最右边的非终端结点开始,将它与其孩子进行比较和有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,故整个构建堆的时间复杂度为O(n)。
在排序时,第i次取堆顶记录重构堆需要用O(logi)的时间(完全二叉树的某个结点到根结点的距离为floor(logi)+1),并且需要取n-1次堆顶记录,因此,重构堆的时间复杂度为O(nlogn)。
所有总体来说,堆排序的时间复杂度为O(nlogn)。因为其对原始记录的排序并不敏感,因此,无论是最好、最坏和平均时间复杂度均为O(nlogn)。
空间复杂度上,它只有一个用来暂存交换数据的单元(temp),也可以说是6的飞起啦。不过由于记录的比较与交换是跳跃式进行,因此堆排序是不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此它并不适合待排序列个数较少的情况
参考资料:
《数据结构——严蔚敏》
《大话数据结构——程杰》